How to Scale a Leaderboard Beyond Basic Redis (2026)

Redis sorted sets are the right foundation for leaderboard ranking. The data structure is genuinely elegant: O(log N) insertions, O(log N + K) range reads, atomic operations, and no lock contention under concurrent writes. Trophy uses Redis under the hood for exactly this reason.
The question isn't whether to use Redis for ranking, it's how much of the surrounding infrastructure you want to build and maintain yourself. A bare sorted set gets you fast global ranking. It doesn't get you segmentation, time-based resets with historical state, a durability guarantee, user profile joins, or rank-change events. Each of those is a separate engineering project.
This post covers what each one involves, what Memcached adds to the picture, and how Trophy functions as an abstraction layer that keeps the Redis performance profile while handling the surrounding complexity.
Why Redis Sorted Sets Beat SQL at Scale
The standard starting point for a leaderboard is an ORDER BY query against a relational database. It works correctly and scales fine until it doesn't — typically somewhere between 50,000 and 500,000 users depending on update frequency. Aa tables grows and update frequency climbs, the sort operation becomes an increasingly expensive full-table pass. Adding an index on the score column helps reads but slows writes. You end up in an arms race between read and write performance that a general-purpose database isn't designed to win.
Redis sorted sets sidestep this entirely. Under the hood, each sorted set is implemented as a skip list — a probabilistic data structure that maintains sorted order on every write rather than sorting at read time. The consequence is that ZADD, ZRANK, and ZREVRANGE are all O(log N) regardless of set size, and range reads are O(log N + K) where K is the number of results returned. Fetching the top 10 users from a set of 10 million takes the same time as fetching from a set of 10,000 — the sort cost is paid incrementally on every write, not in a single expensive query at read time.
A basic TypeScript implementation using ioredis demonstrates the core pattern:
import Redis from 'ioredis';
const redis = new Redis(process.env.REDIS_URL);
// Update a user's score — O(log N)
async function recordActivity(userId: string, value: number): Promise<void> {
await redis.zincrby('leaderboard:weekly', value, userId);
}
// Fetch the top 10 — O(log N + 10)
async function getTopTen(): Promise<Array<{ userId: string; score: number }>> {
const results = await redis.zrevrangebyscore(
'leaderboard:weekly',
'+inf',
'-inf',
'WITHSCORES',
'LIMIT',
0,
10
);
const entries = [];
for (let i = 0; i < results.length; i += 2) {
entries.push({ userId: results[i], score: parseFloat(results[i + 1]) });
}
return entries;
}
// Get a specific user's rank — O(log N)
async function getUserRank(userId: string): Promise<number | null> {
const rank = await redis.zrevrank('leaderboard:weekly', userId);
return rank !== null ? rank + 1 : null; // Convert 0-indexed to 1-indexed
}
This is correct, fast, and handles concurrent writes safely. Redis processes commands sequentially through its single-threaded event loop, so two users updating scores simultaneously never corrupt the sorted set — no SELECT-then-UPDATE race condition, no transaction isolation level to worry about.
At this point, the competing guidance is accurate: Redis sorted sets are the right data structure. The complications start when you extend beyond a single global list.
Five Places Raw Redis Gets Complicated
Segmentation key explosion
A single global leaderboard maps to one sorted set key. The moment you add segmentation (city-level boards, skill-tier boards, friend groups, gym-specific rankings) you're managing one sorted set per segment. A mid-sized fitness app with 50 cities, 3 skill tiers, and 4 activity types has 600 sorted sets to maintain. Every score update potentially touches multiple sets. At 10,000 daily active users averaging two activities each, that's 20,000 write operations touching up to 600 keys per operation in the worst case.
To keep things maintainable as this scales, you need a consistent naming scheme (leaderboard:{type}:{segmentValue}), logic to determine which keys a given user belongs to on every write, a way to enumerate all segments when querying, and a cleanup strategy for segments that become empty. None of this is a Redis limitation, it's just engineering work that scales with the number of segment dimensions you add.
// What segmented writes look like at the application layer
async function recordActivitySegmented(
userId: string,
value: number,
userCity: string,
userSkillTier: string,
activityType: string
): Promise<void> {
const keys = [
`leaderboard:global`,
`leaderboard:city:${userCity}`,
`leaderboard:tier:${userSkillTier}`,
`leaderboard:activity:${activityType}`,
`leaderboard:city:${userCity}:tier:${userSkillTier}`,
];
// Pipeline all writes — but you're still managing N keys per user
const pipeline = redis.pipeline();
for (const key of keys) {
pipeline.zincrby(key, value, userId);
}
await pipeline.exec();
}
This is manageable at 5 segments. At 600, key management becomes a significant operational concern.
Time-based resets and historical state
Resetting a weekly leaderboard at period boundaries sounds simple. It isn't. The naive approach (deleting the key and starting fresh) loses the previous period's final rankings before you've had a chance to announce winners or archive results for later analysis. The standard pattern is to snapshot the old set first, then reset:
async function resetWeeklyLeaderboard(weekKey: string): Promise<void> {
const archiveKey = `leaderboard:weekly:archive:${weekKey}`;
// Snapshot the current set before reset
await redis.zunionstore(archiveKey, 1, 'leaderboard:weekly');
await redis.expire(archiveKey, 60 * 60 * 24 * 90); // Keep 90 days
// Delete the live set to start fresh
await redis.del('leaderboard:weekly');
}
This introduces a race condition: if a score update arrives between the ZUNIONSTORE and DEL, that update is in the archive but not in the new live set. The correct approach uses a Lua script to make the operation atomic:
const resetScript = `
local archiveKey = KEYS[2]
local liveKey = KEYS[1]
redis.call('ZUNIONSTORE', archiveKey, 1, liveKey)
redis.call('EXPIRE', archiveKey, ARGV[1])
redis.call('DEL', liveKey)
return 1
`;
async function atomicReset(weekKey: string): Promise<void> {
await redis.eval(
resetScript,
2,
'leaderboard:weekly',
`leaderboard:weekly:archive:${weekKey}`,
String(60 * 60 * 24 * 90)
);
}
Now add timezone handling. A weekly leaderboard ending Sunday midnight needs to end at Sunday midnight in each user's local timezone, not UTC. You can't reset the global set at a single UTC timestamp without disadvantaging users in later timezones. The correct architecture requires either per-user timezone tracking with per-user period offsets, or a finalisation window that holds the period open until all timezones have passed the boundary, typically 12 to 14 hours after the UTC deadline.
Persistence and durability
Redis is an in-memory store. By default, a Redis restart loses all data. For a leaderboard, that means losing all rankings since the last snapshot. Production deployments need to choose between RDB (periodic snapshots, faster but lossy) and AOF (append-only log, slower but durable) persistence modes, or a combination. Misconfiguring this — or failing to account for it at all — means a Redis node restart can silently wipe weeks of ranking data.
This isn't a hard problem to solve, but it's a configuration and operational concern that needs deliberate attention. A managed Redis service (ElastiCache, Redis Cloud, Upstash) handles this for you at the infrastructure level, but you still need to understand the durability model to know what you're getting.
User data joins
Redis stores user IDs and scores. It knows nothing about display names, avatars, or any other user attributes needed to render a leaderboard. Every leaderboard read requires a join between Redis (for ranks and scores) and your primary database (for user metadata).
async function getLeaderboardWithProfiles(limit: number) {
// Step 1: Get ranked user IDs from Redis
const ranked = await redis.zrevrangebyscore(
'leaderboard:weekly',
'+inf', '-inf',
'WITHSCORES', 'LIMIT', 0, limit
);
const userIds = ranked.filter((_, i) => i % 2 === 0);
// Step 2: Fetch user profiles from your database
const profiles = await db.query(
'SELECT id, name, avatar_url FROM users WHERE id = ANY($1)',
[userIds]
);
const profileMap = new Map(profiles.map(p => [p.id, p]));
// Step 3: Merge
return userIds.map((userId, index) => ({
rank: index + 1,
userId,
score: parseFloat(ranked[index * 2 + 1]),
name: profileMap.get(userId)?.name ?? 'Unknown',
avatarUrl: profileMap.get(userId)?.avatar_url ?? null,
}));
}
Two round trips on every leaderboard render. For read-heavy leaderboards, this pattern drives significant database load. The standard mitigation is to cache the merged result — which then introduces cache invalidation complexity on top of the Redis and database layers.
Rank-change event blindness
Redis has no concept of a user's rank changing because someone else scored more. When User A's score update pushes User B from rank 9 to rank 10, Redis processes User A's ZINCRBY correctly — but nothing notifies User B. Building a rank-change notification system on top of Redis requires polling (expensive), a separate event stream (significant architecture), or a post-write rank comparison (latency and consistency trade-offs). This is one of the more underappreciated pieces of leaderboard infrastructure, and it's entirely absent from the Redis documentation and most tutorials.
What Memcached Adds — and Doesn't
Memcached is a simple key-value cache with no sorted data structure primitive. It cannot implement leaderboard ranking natively — there's no Memcached equivalent of ZADD or ZRANK. Where Memcached appears in leaderboard architectures, it's as a read cache layer in front of Redis or a database: pre-computed leaderboard snapshots are stored in Memcached with a short TTL and served from there to reduce Redis or database read load.
// Typical Memcached caching layer in front of Redis
async function getCachedLeaderboard(key: string, ttlSeconds = 30) {
const cached = await memcached.get(key);
if (cached) return JSON.parse(cached);
const fresh = await getLeaderboardFromRedis(key);
await memcached.set(key, JSON.stringify(fresh), ttlSeconds);
return fresh;
}
This pattern makes sense at very high read volumes — if thousands of users are viewing the leaderboard simultaneously and fresh-to-the-second accuracy isn't required, serving from Memcached reduces Redis round trips. But it doesn't solve segmentation, time-based resets, persistence, user data joins, or rank-change events. It adds a caching layer on top of the existing Redis problems, along with its own staleness and invalidation considerations.
Trophy's Architecture
Trophy uses Redis sorted sets for real-time ranking — the same data structure and the same O(log N) performance profile. The difference is that Trophy handles the surrounding infrastructure as a managed layer, so the problems above don't land in your codebase.
The architecture sits across three components:
Redis handles real-time ranking for all active leaderboard periods. Sorted sets are maintained per leaderboard per period per segment. Segmentation key management, atomic period resets, and the Lua scripts required for safe transitions are internal to Trophy's infrastructure.
PostgreSQL materialises ranking data for durability and historical queries. Completed leaderboard periods are persisted to Postgres, which means historical runs are queryable without relying on Redis TTL management or archived keys. It also means a Redis node restart doesn't wipe live ranking data — writes to Redis are backed by Postgres persistence.
An event pipeline sits on top of both. When a user's rank changes — including when their rank shifts because another user scored more — Trophy detects the transition and fires a leaderboard.rank_changed webhook. Period boundaries trigger leaderboard.finished and leaderboard.started events. These are the re-engagement hooks that raw Redis can't emit.
From the application side, the integration is three API calls:
import { TrophyApiClient } from '@trophyso/node';
const trophy = new TrophyApiClient({ apiKey: process.env.TROPHY_API_KEY });
// 1. Identify users with segmentation attributes — Trophy manages key routing internally
await trophy.users.identify(userId, {
name: 'Sam Okafor',
attributes: {
city: 'london',
skill_level: 'intermediate',
},
});
// 2. Send activity — Trophy writes to all relevant sorted sets atomically
const response = await trophy.metrics.event('workouts_completed', {
user: { id: userId, tz: 'Europe/London' },
value: 1,
});
// Rank positions for all relevant leaderboards come back inline
// No separate ranking query, no user data join required on your side
console.log(response.leaderboards);
// 3. Fetch a segmented leaderboard for display
const londonBoard = await trophy.leaderboards.get('weekly-workouts', {
limit: 10,
userAttributes: 'city:london',
});
// Historical runs are available without any archival work on your end
const lastWeek = await trophy.leaderboards.get('weekly-workouts', {
limit: 10,
userAttributes: 'city:london',
run: '2026-04-07', // Period start date of the previous week
});
The rank-change webhook requires a handler in your application, but the detection and delivery are handled by Trophy:
// Webhook handler — Trophy fires this when any user's rank shifts
app.post('/webhooks/trophy', async (req, res) => {
const event = req.body;
if (event.type === 'leaderboard.rank_changed') {
const { userId, leaderboardKey, rank, previousRank } = event.data;
if (rank > previousRank) {
// User has dropped — re-engagement trigger
await sendPushNotification(userId, {
title: "You've been overtaken",
body: `You've dropped to rank ${rank} on the ${leaderboardKey} leaderboard this week.`,
});
}
if (rank < previousRank) {
// User has climbed — positive reinforcement
await sendPushNotification(userId, {
title: 'You moved up',
body: `You're now ranked #${rank} this week. Keep going.`,
});
}
}
if (event.type === 'leaderboard.finished') {
// Period has closed — announce winners, trigger recap emails
const { leaderboardKey, topRankings } = event.data;
await sendWeeklyRecapEmail(topRankings);
}
res.sendStatus(200);
});
The rankings configuration and rest conditions are all managed through the Trophy dashboard, meaning all members of the product team, including non-technical colleagues, can be involved in the build.
Teams can also make use of Trophy's built-in leaderboard analytics dashboards which help understand leaderboard activity, balance and competitiveness.
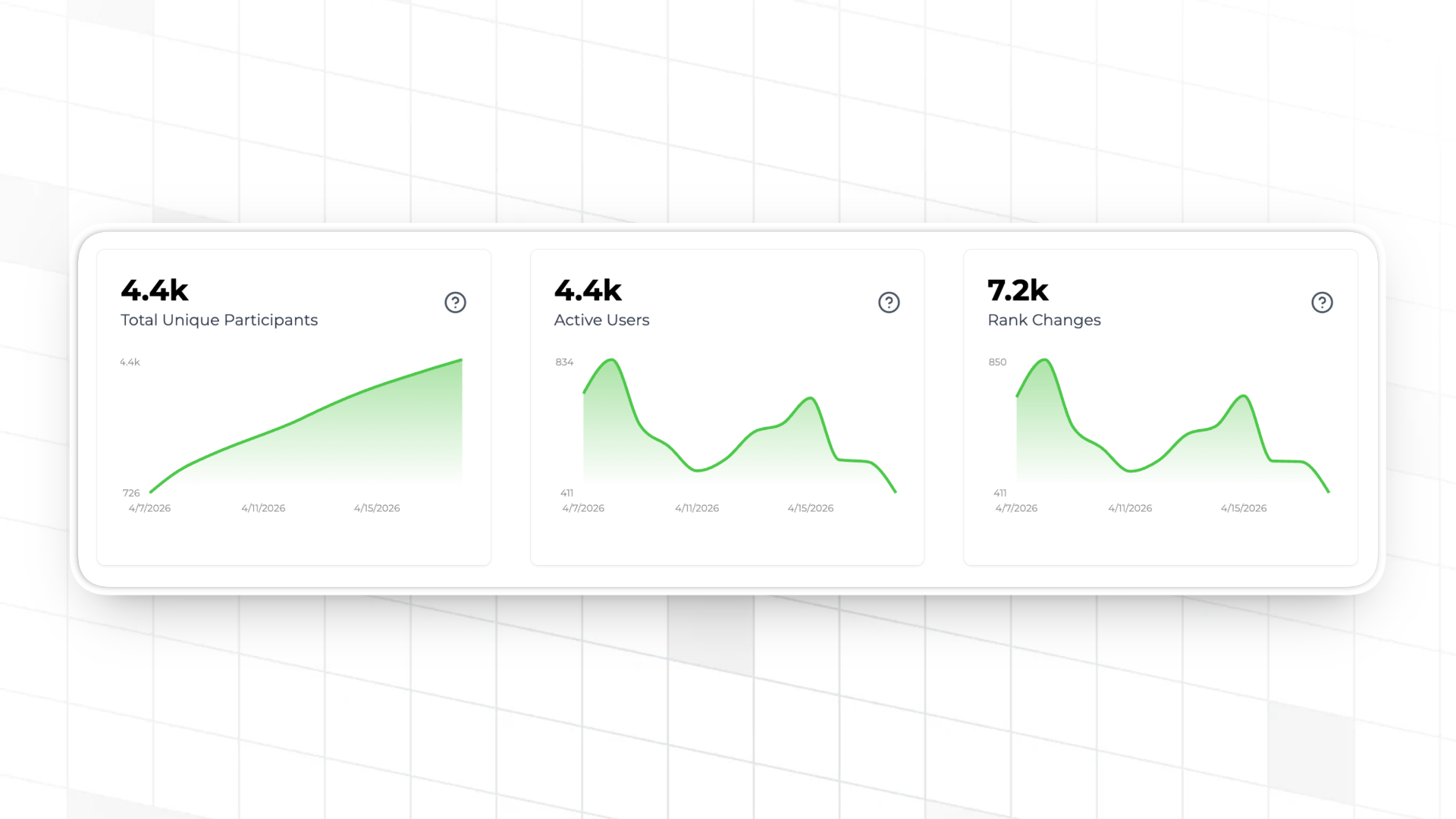
What You're Actually Trading Off
Running Redis leaderboard infrastructure yourself means owning the following, in addition to the core sorted set operations:
- Key schema management — naming convention, enumeration, and cleanup for all segment keys
- Atomic reset logic — Lua scripts for safe period transitions without race conditions
- Persistence configuration — RDB vs AOF trade-offs, backup strategy, recovery procedures
- Timezone-aware period management — per-user timezone tracking and finalisation windows
- Historical state archival — TTL management or database snapshots for past period queries
- User profile join layer — round trips between Redis and your database on every render, plus caching strategy
- Rank-change event pipeline — polling or event streaming to detect rank transitions from third-party score updates
- Redis cluster management — sharding decisions, replica configuration, monitoring if you reach 10M+ member sets
- Read caching layer — Memcached or application-level cache for high-volume read scenarios
None of these are insurmountable. Senior engineers build all of them regularly. The honest question is whether any of that work is the part of your product that differentiates you from competitors. If the answer is no (and for most consumer apps it is) Trophy provides the same Redis performance with that list already handled.
For a more detailed look at the segmentation design decisions and what breakdown attributes to use for your app category, How Strava Uses Segmented Leaderboards to Drive Engagement covers the psychology and configuration in more depth. For the full implementation walkthrough from first event to live rankings, see How to Build a Leaderboard for Your App, and the official Trophy leaderboard documentation.
FAQ
Does Trophy actually use Redis, or is that a simplification?
Trophy uses Redis sorted sets for real-time ranking — the same data structure described in this post. The O(log N) performance characteristics apply. The difference is that Trophy manages the Redis infrastructure, key schema, persistence configuration, and operational concerns. You interact with a REST API; the sorted set operations happen internally.
What's the performance difference between querying Trophy versus querying Redis directly?
A direct Redis ZRANK or ZREVRANGE call is a sub-millisecond in-memory operation — as fast as it gets. Trophy adds one HTTP round trip to that, typically 20–50ms depending on region. For leaderboard display (which is a UI interaction, not a hot path) this is imperceptible. For real-time ranking updates where you want the user's updated position returned inline (e.g., immediately after a score update), Trophy returns rank data in the event response within 200-300ms, eliminating the need for a separate ranking query after the write.
Should I cache Trophy's leaderboard responses?
For display use cases, yes. Caching for 30–60 seconds on your side reduces API calls and is consistent with standard leaderboard UX — users don't need rankings accurate to the millisecond when viewing a leaderboard screen. Trophy returns fresh data on every request; the caching decision is yours. For real-time feedback immediately after a user's own activity (showing their updated rank), use the rank data returned directly in the metric event response rather than polling the leaderboard endpoint.
What happens to my leaderboard if Trophy experiences downtime?
Design your integration to degrade gracefully — queue metric events for retry and serve cached leaderboard data during any outage. This is the same resilience pattern you'd apply to any external service and the same pattern you'd need to implement for a managed Redis provider. Trophy's 99.9% uptime SLA and infrastructure redundancy are detailed on the status page.
At what scale does building Redis leaderboards in-house become worth it?
The threshold is usually centered around unusual requirements that managed platforms don't support i.e. custom ranking algorithms, proprietary tie-breaking logic, or integration constraints specific to your stack. However for most apps with standard leaderboard requirements, the build-in-house path typically costs more in upfront engineering time and ongoing maintenance than it saves in platform fees.
Where to Go Next
The Trophy Leaderboards documentation covers the full configuration reference: leaderboard types, ranking methods, breakdown attribute setup, and the webhook event schema for leaderboard.rank_changed and leaderboard.finished.
For the implementation walkthrough — from first metric event to a live segmented leaderboard with rank-change notifications — see How to Build a Leaderboard for Your App.
The segmentation design decisions (when to split, what attributes to use, how small to make groups) are covered in How Strava Uses Segmented Leaderboards to Drive Engagement.
Get the latest on gamification
Product updates, best practices, and insights on retention and engagement — delivered straight to your inbox.